
Scott Grant




In the distant past when I completed my doctorate, the deep learning boom hadn’t yet taken off. The year was 2012. We were charmed by Watson, even if it didn’t know much about Toronto’s airport. One Bitcoin cost anywhere from two to twelve dollars. We used graphics processing units to render graphics, of all things. What a halcyon age.
Back then, our version of machine learning still felt like magic. We spent a lot of time working with topic models, latent variables, and other arcane spells. If you threw a bunch of documents together - for example, all of the Wikipedia pages - you could wrap a topic model around them to find topics. In this context, a topic is a latent or pre-existing association between words across all of the documents you’re modelling, but not exactly what you think of when I say “topic.” You might discover that some of the discovered topics are intuitively described as “animals” or “world leaders” or “people from Kingston, Ontario.” However, if you cast the spell again to generate a new topic model, you might find that “animals” is no longer a topic, but maybe “cats” is, and what happened to those people from Ontario because all I see is the “draft history of the Detroit Pistons” maybe? What the heck is a topic anyway? These models worked on their own time and, aside from some gentle nudges, largely did what they wanted. After all, how many latent variables are in Wikipedia anyway? Three hundred? Five? Magic, I say. And did I mention that I had to walk uphill to and from the lab? Get off of my lawn!
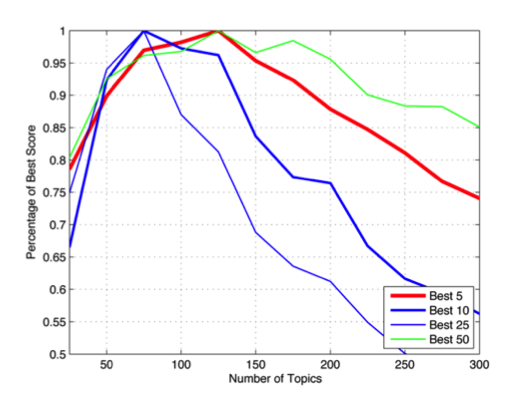
This questionable graph suggests the answer is somewhere in the 75 to 125 topic range. Don’t use 100, as it’s not optimal! Unfortunately, I can’t remember which dataset was used to generate this graph. Oops!
At the time, I felt like I had a really solid grasp on the state of machine learning. We spent a lot of time trying to understand what kind of similarity these models were actually capturing, and moving away from simply listing the discovered topics and calling it a day. I got pretty good at explaining how machine learning didn’t always capture similarity in the way that we assumed it would, that our bias could lead to some really bad conclusions, or that the source data held detail that could skew a model’s result in some very dangerous ways.
Then I graduated, watched my two beautiful kiddos get better than me at video games, and continued to grow as a professional software developer outside of academia.
At the same time, some very smart people started training some neural networks in some very smart ways on some very powerful computers.
These new approaches aren’t just good. In many areas, they’re scary good. They’re doing things that we didn’t think were possible without a lot of serious human intervention. This isn’t to say that they aren’t still without their problems; look at how algorithms struggle with skin tone or social bias. Things are moving quickly. I certainly didn’t expect to feel like a dinosaur in only six years.
Nonetheless, the state of machine learning has changed. Machine learning has changed. Need an oil painting of your house? Apply a style transfer. There’s an app for that. Want to whoop the world’s best poker players? Why not? The cloud is right over there, ready to spin for a few human-years and a few million hands of cards. Should only take a day or so. Time flies when you’re having fun.
I’ve been meaning to really catch up on these changes. As a result, I’m going to work through the Deep Learning textbook, which is available online or on paper through Amazon. All of my code will end up here on GitHub. Please feel free to work through the book as well - I’d love to chat with other people who know the material or who are learning!
And hey, maybe we can all create a startup at the end or something, right? That’s what you do! Deep learning on the blockchain? Style transfer Ethereum smart contracts? Look, I made it this far without saying “I’ve got some deep learning to do, ha ha ha,” so please let me have just one lame joke. Singularity Blockchain? Bueller?